
本記事では、教師あり学習と教師なし学習とは何か、またその違いついてざっくりとお話ができたらなと思います。
機械学習とは
教師ありと教師なし学習のことを知るには、機械学習を知る必要があります。
機械学習とはデータを学習することでデータのパターンやルールを抽出したり、予測や分類を行うことをいいます。
また、実際にデータを学習して出力結果を出すものを機械学習モデルと言い、そのモデルにデータを与えてどのように学習させるかの手順のことを機械学習アルゴリズムと言います。
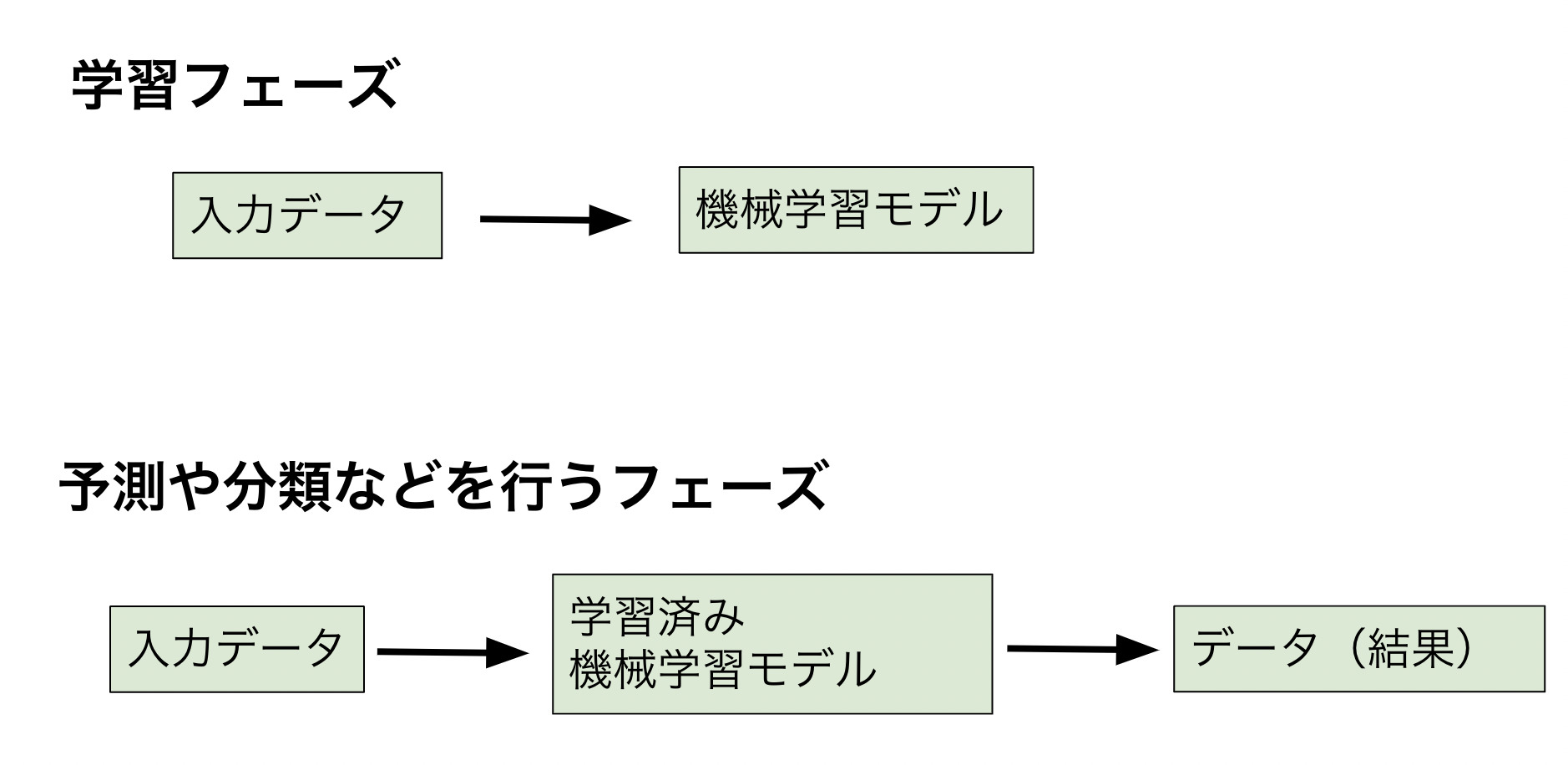
機械学習では、予測や分類などの結果を出すまでい2段階のフェーズがあります。学習フェーズと結果を出すフェーズです。
学習フェーズでは与えられるデータを元に、そのデータのパターンや特徴を見つけてモデルを作成します。次に、結果を出すフェーズでは、学習済みのモデルに、新たにデータを与えることで、そのデータに関した予測や分類などの結果を出力します。
機械学習では学習フェーズが重要視されていて、多くの研究がされています。
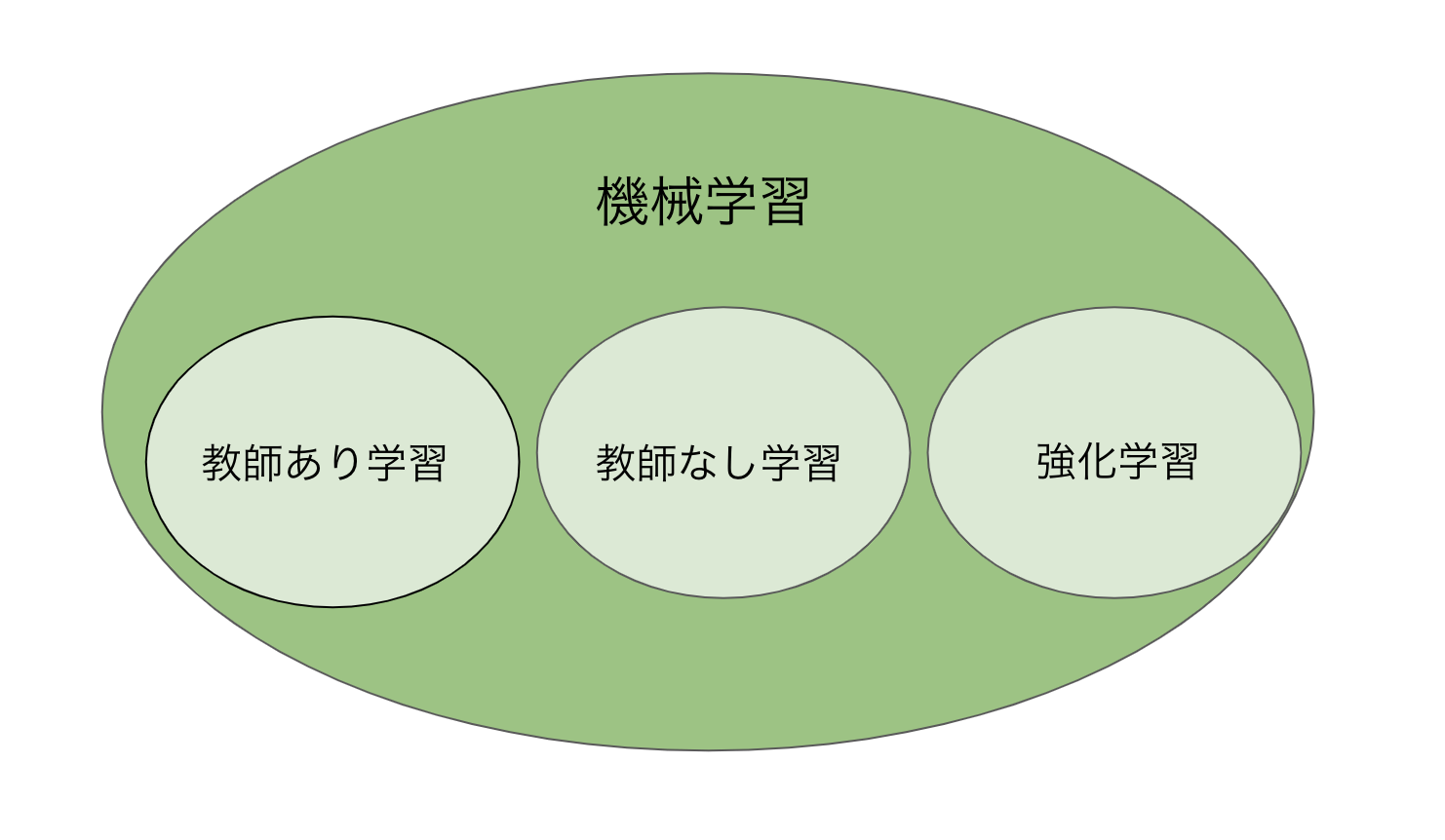
この機械学習の手法は、教師あり学習、教師なし学習、強化学習に大きく3つに分類されます。
一般的には、教師あり学習がよく使われている印象があります。
教師あり学習とは
教師あり学習とは、正解データ(ラベル情報)を含む入力データを学習することで、予測や分類を行う機械学習の手法です。
では、正解データとは何なのでしょうか。
例えば、アイスの売り上げを、その日の気温から予測したい場合を考えます。

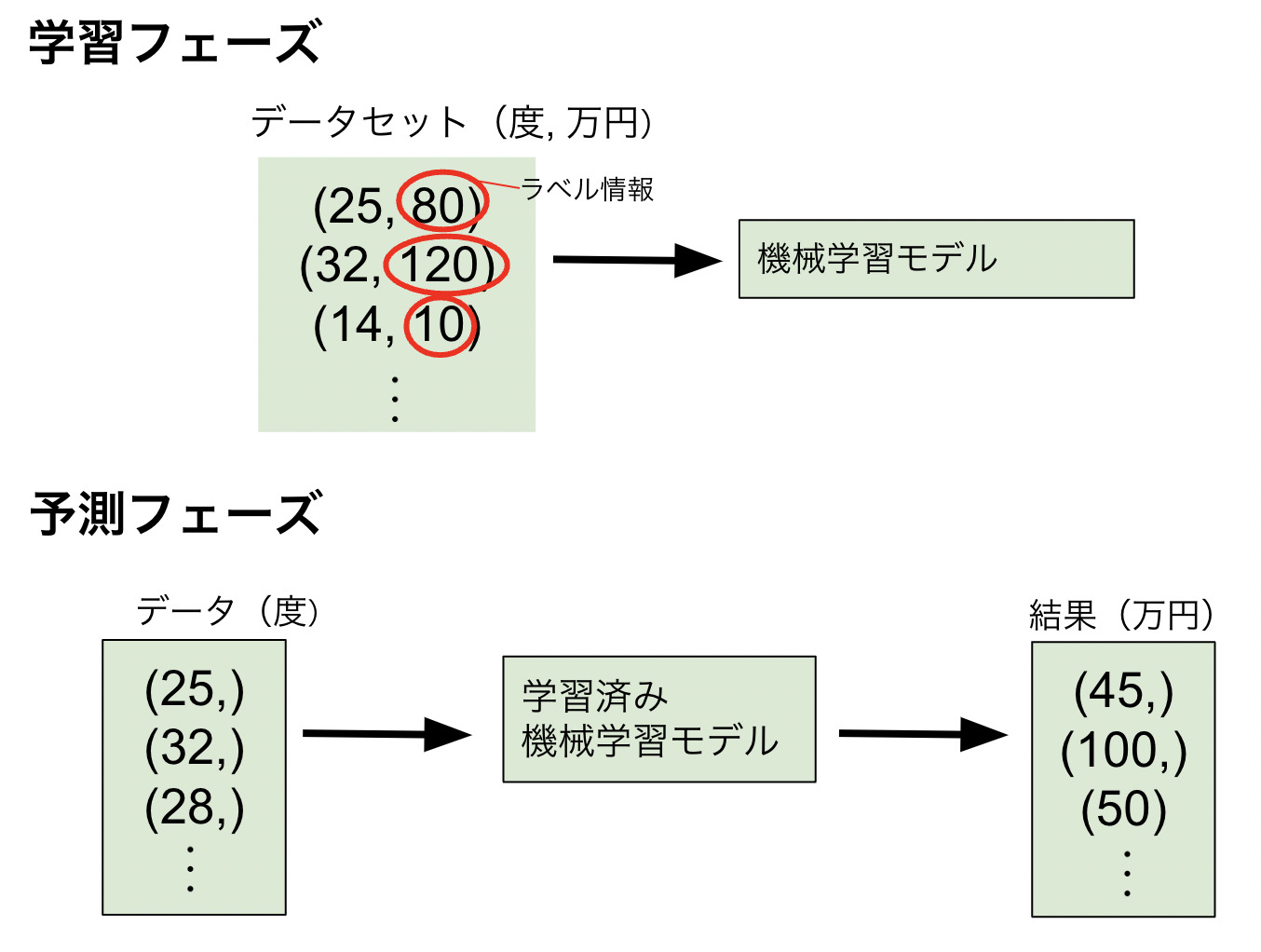
過去の気温のデータに対して、その気温のときの売り上げがわかっているとき、その売り上げというのは気温データに対する正解データになります。このデータセットを図で示すと以下のようになります。25度のときは80万円の売り上げ、32度のときは120万円の売り上げ、14度のときは10万円の売り上げがあったというデータセットになります。

このデータセットをモデルに学習させた後、新規の気温データに対する売り上げを予測してもらうのです。
- 過去の売り上げデータからモデルを学習します。
- 学習したモデルに対して、25度、32度、28度.....の気温のときの予測を行います。その結果、45万円、100万円、50万円...と予想結果が出力されるのです。
説明変数と目的変数
機械学習で扱うデータは、説明変数と目的変数と呼ばれます。説明変数とは、現象や値を説明する変数で気温データが該当します。
目的変数とは、説明変数によって発生した結果を表す変数で売り上げデータが該当します。機械学習では、説明変数と目的変数を用いて学習と予測を行います。
テストデータと学習データ
教師あり学習では、モデルを学習する学習データ(入力データ)とは別にテストデータを用意する必要があります。
テストデータはモデルがきちんと精度の高い予測を出してくれるのかを検証するためのデータです。
学習済みのモデルを獲得しても、新たな未知のデータに対する予測精度が悪いと何の意味もありません。その予測精度を確認するためにテストデータが必要なのです。
メリットとデメリット
教師あり学習は、正解データを含むデータを学習するので、学習スピードが速く、出力される結果の精度が高いです。
しかし、学習するときに大量のデータが必要になります。この大量のデータ(ビックデータ)収集は時間とコストがかかるのでデメリットの一つとも言えます。
また、入力データの中に誤ったデータが入っているとモデルの精度が悪くなります。そのため、学習前に入力データを前処理してきれいな状態にする必要があります。
メリット
- 学習スピードが速い
- 出力結果の精度が高い
デメリット
- 入力データの中に誤ったデータが入っているとモデルの精度が悪くなる
- 学習に大量のデータが必要であり、コストと時間がかかる
活用例
教師あり学習は様々なところで活用されています。正解データさえあれば、モデルを学習し精度の高い予測を出してくれるので、非常に扱いやすい手法だからです。例としては以下のものがあります。
- 電子メールのスパム判定
- 株価や住宅価格の予測
- カメラに映る映像中の物体の判定
- 音声認識として誰が話しているのかを予測
- 店舗の売り上げ予測
電子メールのスパム判定では、私たち人間が迷惑ボックスに入れたメールを、スパムメールという正解データと認識してモデルが学習します。
そして、学習したモデルが新たに来るメールに対して、スパムメールなのか普通のメールなのかを分類するのです。
教師なし学習とは
教師なし学習とは、正解データ(ラベル情報)を含まない入力データを学習して、データの規則性や特徴を見つけ出す手法のことをいいます。クラスタリング、次元削減といった目的で使われることが多いです。
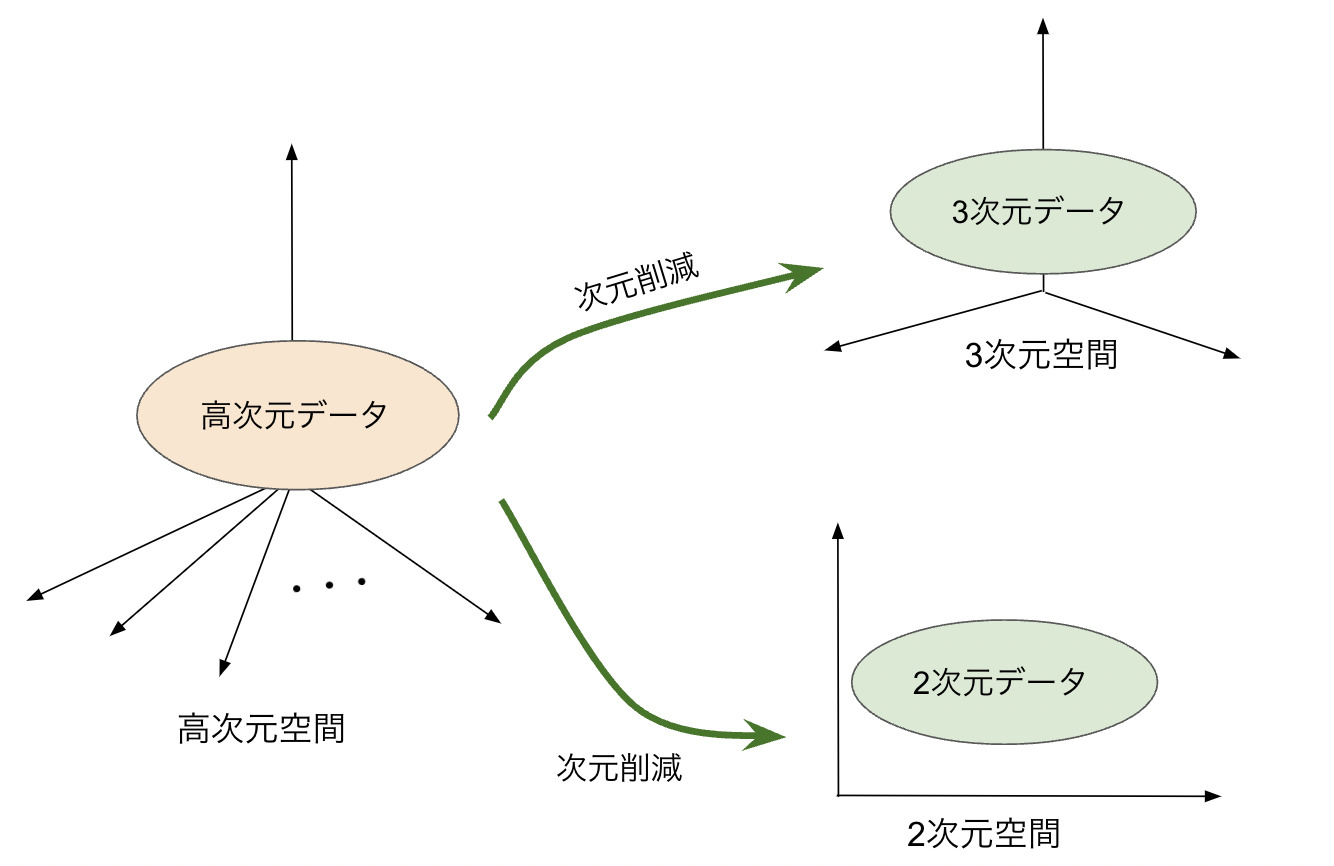
次元削減
次元削減とは、高次元のデータを可能な限り情報を残したまま低次元データに変換する手法のことです。
データの特徴を見るために空間にプロットすることを可視化するといいます。データを可視化することは様々なメリットが存在します。
- わかりやすくデータを理解できる
- データ間の関係性を見ることができる
- 新たな気づきや知見の獲得につながる
私たち人間が可視化によって見やすい次元は3次元空間までであって、4次元以上になると非常にわかりにくいです。
そのため、4次元以上の高次元データを、人間が見やすいように可視化するために次元削減を用います。
また、高次元のデータをモデルが学習するとき、非常に時間がかかってしまいます。そのため、次元削減を行うことで低次元へ落とし学習を高速にすることができるのです。
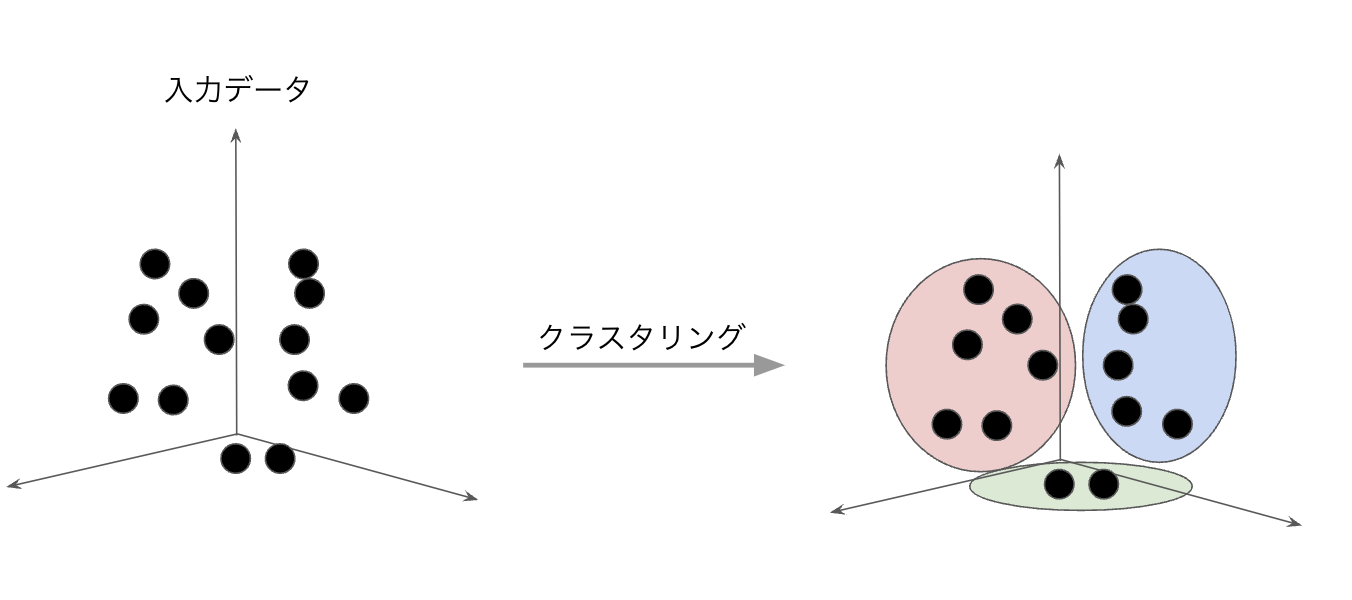
クラスタリング
クラスタリングは入力データの特徴を抽出し、その特徴の類似度にもとづいて、データをグループ分けする手法です。
クラスタリングは様々なところで活用されており、amazonのオススメの商品の表示などがあります。過去の購買データをクラスタリングし、同じグループの商品を紹介したりしています。
教師あり学習と教師なし学習の違い
教師あり学習と教師なし学習の違いは、入力データの違いと、用途(タスク)にあります。
教師あり学習と教師なし学習の違いについてまとめ
| 教師あり学習 | 教師なし学習 | |
| 学習データ | 学習データに正解データを含む。 | 学習データに正解データを含まない |
| タスク | 予測, 分類 | 学習データのパターンやルール抽出 |
最後に
ここまで読んで頂きありがとうございます。
質問や修正リクエストをお待ちしています。